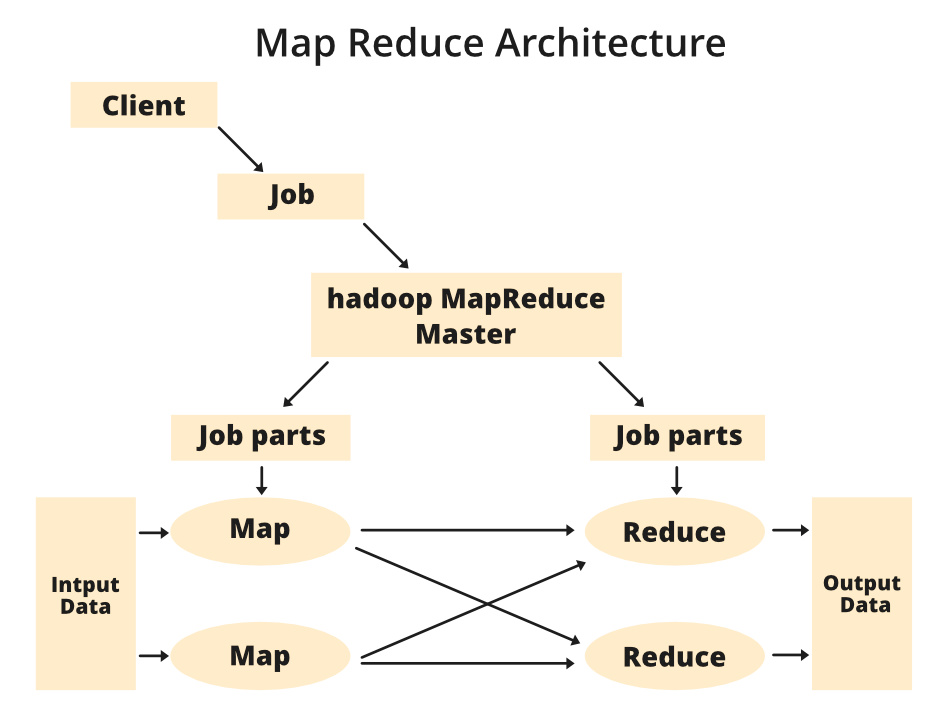
 MapReduce Architecture is the backbone of Hadoop’s processing, offering a framework that splits jobs into smaller tasks, executes them in parallel across a cluster, and merges results.
MapReduce Architecture is the backbone of Hadoop’s processing, offering a framework that splits jobs into smaller tasks, executes them in parallel across a cluster, and merges results. MapReduce is the processing engine of Hadoop that processes and computes large volumes of data. It is one of the most common engines used by Data Engineers to process Big Data.
MapReduce is the processing engine of Hadoop that processes and computes large volumes of data. It is one of the most common engines used by Data Engineers to process Big Data.